
En este último post de la serie de bombas zip, voy a hablaros de un nuevo método que ha surgido en el último mes: las bombas de superposición. Con este tipo de bombas se ha llegado a conseguir la mayor tasa de descompresión de todos los tiempos:de 46 MB a 4.5 Petabytes.
El Concepto
Esta clase de bomba que ha sido creada por David Fifield tiene algo muy distinto a las de los anteriores posts: no utiliza la recursividad. En su lugar, utiliza el solapamiento de ficheros. Esto implica que tras la primera descompresión se expande completamente, por lo que no se puede parar con las medidas de seguridad que toman los antivirus y sistemas operativos con los anteriores tipos de bomba.
En el primer post vimos como por el método de compresión DEFLATE de Zip no se puede obtener una tasa de compresión mayor que 1:1032. Por ello hasta ahora se había utilizado la recursión. Pero tanto la bomba recursiva como la bomba quine son ofensivas si solo se descomprimen una vez, y no recursivamente. En este caso se ha conseguido que de una sola descompresión se alcance un tamaño cuadrático al de la entrada, superando la tasa de compresión de DEFLATE.
Técnica de superposición
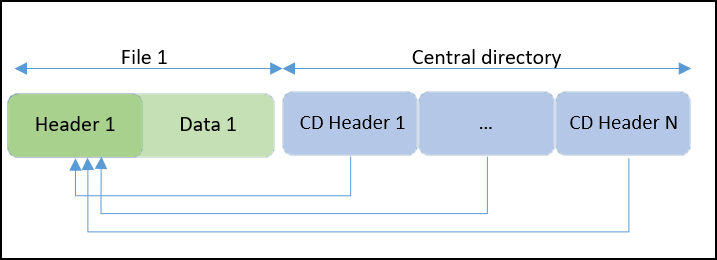
Para entender cómo funciona esta nueva técnica, se ha de entender la estructura de Zip. Tal y como podemos ver a continuación, un Zip está formado por los archivos que contiene, cada uno de ellos compuesto por una cabecera y el contenido del archivo. Por último, encontramos el directorio central, que contiene las cabeceras de estos ficheros y una referencia a los mismos:

Lo que Fifield consiguió fue que los headers del directorio central apuntasen todos a un mismo archivo. De esa forma, aunque el zip solo contiene un archivo de unos pocos bytes, si se crean muchos headers en el directorio central al descomprimir el programa considerará que hay miles de archivos, pues todos los headers apuntan al mismo:
Así ha conseguido un ratio muchísimo mejor que el que proporciona DEFLATE, pasando de 1:1032 a 1:21277.
Problemas de la teoría a la práctica
Sin embargo, esto solo funciona en la teoría, ya que surge un problema entre el archivo y el directorio central: el nombre del header del archivo debe coincidir con el del directorio central. Si en el directorio central pone «Header 1», «Header 2», … , «Header N»; y solo existe el archivo con el Header 1, se producirá un error al intentar descomprimir los demás. Y tampoco es posible poner en el directorio central siempre la cabecera «Header 1», ya que el sistema no permite que se repitan los nombres.
Dado que la mayor parte del peso de un zip está en los datos (en este caso, en «Data 1») no hay problema en añadir cuantos headers se requiera, pues un header de un archivo solo ocupa 31 bytes. Por esto lo siguiente que se probó es a introducir muchos headers y un solo contenido con los datos:

El problema de esto es que cuando se va a descomprimir el primer archivo, donde el programa espera encontrar datos encuentra el header del siguiente archivo, con lo que produce de nuevo un error.
Versión final
Para arreglar este problema, lo que se hizo fue buscar la forma de «escapar» el siguiente header para que el programa lo interprete como datos, pero continue siendo un header para que la siguiente referencia del directorio central continúe funcionando. Podemos conseguirlo gracias a que en Zip hay bloques que no se comprimen y se deben copiar tal cual en la descompresión, y estos bloques van precedidos de una cabecera de 5 bytes que indica el tamaño del bloque que se tiene que copiar directamente. Mediante estas cabeceras podemos «escapar» todas las cabeceras hasta llegar al contenido del archivo:
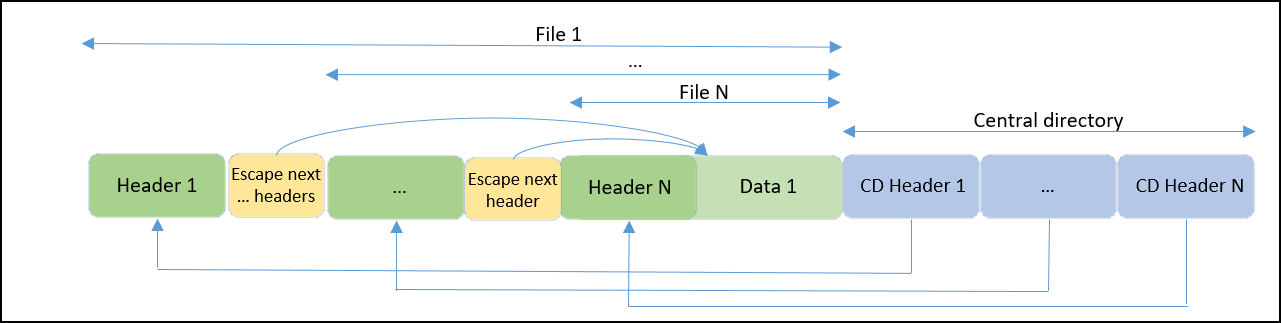
Veamos un ejemplo de cómo funcionaría con N=3: El programa empieza consultando la primera cabecera del directorio central, «CD Header 1», que le redirige a «Header 1». Zip procede a ejecutar lo que haya detrás de «Header 1». Se encuentra la cabecera «Escape next 2 headers», con lo que el programa escribe en el output tal y como están las cabeceras «Header 2», «Escape next header» y «Header 3». Después, se encuentra con «Data 1» y lo descomprime en el output. A continuación pasa al siguiente fichero, consultando la siguiente cabecera del directorio central, «CD Header 2», que le redirige a «Header 2». Zip procede a ejecutar lo que hay detrás, y se encuentra con la cabecera «Escape next header» por lo que escribe en el output la cabecera «Header N» y pasa a descomprimir «Data 1». Para terminar el programa pasa a la última cabecera del directorio central, «CD Header N», le redirige a la cabecera «Header N» y descomprime en el output «Data 1».
En este ejemplo hay 3 cabeceras de ficheros de 31 bytes, 2 cabeceras de escape de 5 bytes, un fichero con los datos comprimidos y 3 cabeceras del directorio central de 1 byte. Si ponemos un fichero comprimido en «Data 1» de 1000 bytes, tenemos un total de 1106 bytes. Ese fichero estará lleno de ceros para obtener la máxima tasa de descompresión de DEFLATE, por lo que al descomprimirse se convierte en 1.032.000 bytes. Al repetirse 3 veces, tenemos 3.096.000 bytes. Más las cabeceras escapadas, hacen un total de 3.096.108 bytes a partir de 1.106 bytes.
David Fifield ha conseguido optimizar esto hasta el punto de conseguir una tasa de descompresión cuadrática, con la que de un archivo comprimido de 42kB se obtiene un archivo de 5.5GB, y con un archivo de 46MB se obtienen 4.5 PB.
Puedes descargarte tanto las bombas zip como el código fuente del programa que las genera en el blog de David Fifield. Pero ten cuidado, porque a día de hoy funciona y si lo intentas descomprimir se bloqueará tu ordenador. En ese blog también tienes explicado más detalladamente todo el proceso de construcción y optimización de la bomba zip.
Con esta entrada acabo la serie de bombas zip, tras haber mostrado las bombas recursivas, las bombas quine y las bombas de superposición.
Lethani.
Interesting